画像認識の代表的なタスクとして、「分類」「物体検知」「セグメンテーション」がありますが、その中で自分が最も使うのが物体検知です。一般画像には多くの物体が写り込んでいることが多く、その中で対象とする物体を正確に検知したいというニーズが多いからでしょう。認識の「粒度」で言えばセグメンテーションの方が高く思えますが、多くのセグメンテーション手法が行うのはピクセルごとのクラス分類であり、画像の中のインスタンスを分離してはくれません。つまり、例えばその写真に自動車が何台写っていようがそれを区別せず「自動車」としてピクセルをクラス分けするのみです。Mask RCNNのようにインスタンスを意識したセグメンテーション技術が充実してくるまでは、矩形で領域を検知する物体検知がニーズの主流となりそうです。
この物体検知、実応用において求められる水準をご存知でしょうか。下の画像はドライブレコーダーの画像から歩行者と自動車を検知したものです。検知をミスしているのがわかりますか?

ひとつは検知している歩行者の左にもう一人いる歩行者を検知できていないこと。もうひとつは右側中央で信号待ちをしている車(ヘッドライトだけが写っています)が検知できていないこと。どちらも簡単な検知対象ではありませんが、人間が注意深く観察すれば検知できるものです。画像認識の世界では(専門家の)人間が注意深く判定できる率を理論上の判定限度(ベイズエラー)とすることが多く、こうした検知ミスをなくしていくことが画像認識の精度をあげていくポイントとなります。
次の写真ではどうでしょうか。

人が密集していて、人間の目にも明確な検知は困難ですが、良く頑張っているといえるかもしれません。目立つところでは、横断歩道を渡る三人の人を二人と検知しています。また、遠くに小さく写る自動車の検知をミスしています。例えば自動運転のために物体検知技術を使おうとすれば、こうした検知をいかに成功させるかが決定的な違いをもたらすことになるのです。
物体検知に求められるのは精度だけではありません。これも自動運転がイメージしやすいと思いますが、物体検知ではライブビデオからのリアルタイム検知が要求されることが多く、検知の速度が大きな要件になります。悩ましいことに一般に精度と速度は相反する関係にあり、高速検知と高精度検知を同時に実現することは難しい要求です。
Deep Learningは見積もりの難しい技術で、実験で精度を確認していくしかありません。科学的に実験を積み上げていくには、確かなフレームワークと評価基準が必要です。今回はKeras/TensorflowでSSD系の開発をするベースにさせて頂いている実装をご紹介し、次回以降にさらに物体検知を深堀りしてみようと思います。その実装がこちらです。
SSDのKeras実装としては https://github.com/rykov8/ssd_keras がありますが、わかりやすく実装されているところ、物体検知の代表的な評価基準であるmAP(mean Average Precision)を測定する枠組みが提供されているところから、個人的にはPierluigi Ferrariさんの実装が気に入ってベースに使わせて頂いています。
まずは実装に含まれているSSD実装の学習を実際に行ってみて、mAPが出ることを確認します。SSD512の学習用のコードを添付します。ファイルパスなどは環境にあわせて変更して下さい。GitHubのFerrariさんのコードをクローンし、説明にあわせてVGG16のpretrained weightや学習画像をセットすればあとはこのコードを流すだけで学習が始まるはずです。
from models.keras_ssd512 import ssd_512
from keras_loss_function.keras_ssd_loss import SSDLoss
from keras_layers.keras_layer_AnchorBoxes import AnchorBoxes
from keras_layers.keras_layer_DecodeDetections import DecodeDetections
from keras_layers.keras_layer_DecodeDetectionsFast import DecodeDetectionsFast
from keras_layers.keras_layer_L2Normalization import L2Normalization
from ssd_encoder_decoder.ssd_input_encoder import SSDInputEncoder
from ssd_encoder_decoder.ssd_output_decoder import decode_detections, decode_detections_fast
from data_generator.object_detection_2d_data_generator import DataGenerator
from data_generator.object_detection_2d_geometric_ops import Resize
from data_generator.object_detection_2d_photometric_ops import ConvertTo3Channels
from data_generator.data_augmentation_chain_original_ssd import SSDDataAugmentation
from data_generator.object_detection_2d_misc_utils import apply_inverse_transforms
import tensorflow as tf
from keras.backend.tensorflow_backend import set_session
img_height = 512 # Height of the model input images
img_width = 512 # Width of the model input images
img_channels = 3 # Number of color channels of the model input images
mean_color = [123, 117, 104]
swap_channels = [2, 1, 0]
n_classes = 20
scales_pascal = [0.07, 0.15, 0.3, 0.45, 0.6, 0.75, 0.9, 1.05]
scales = scales_pascal
aspect_ratios = [[1.0, 2.0, 0.5],
[1.0, 2.0, 0.5, 3.0, 1.0/3.0],
[1.0, 2.0, 0.5, 3.0, 1.0/3.0],
[1.0, 2.0, 0.5, 3.0, 1.0/3.0],
[1.0, 2.0, 0.5, 3.0, 1.0/3.0],
[1.0, 2.0, 0.5],
[1.0, 2.0, 0.5]] # The anchor box aspect ratios used in the original SSD300; the order matters
two_boxes_for_ar1 = True
steps=[8, 16, 32, 64, 128, 256, 512]
offsets=[0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5]
clip_boxes = False # Whether or not to clip the anchor boxes to lie entirely within the image boundaries
variances = [0.1, 0.1, 0.2, 0.2] # The variances by which the encoded target coordinates are divided as in the original implementation
normalize_coords = True
# 1: Build the Keras model.
# K.clear_session() # Clear previous models from memory.
config = tf.ConfigProto(
gpu_options=tf.GPUOptions(
visible_device_list="0", # specify GPU number
allow_growth=True
)
)
set_session(tf.Session(config=config))
model = ssd_512(image_size=(img_height, img_width, img_channels),
n_classes=n_classes,
mode='training',
l2_regularization=0.0005,
scales=scales,
aspect_ratios_per_layer=aspect_ratios,
two_boxes_for_ar1=two_boxes_for_ar1,
steps=steps,
offsets=offsets,
clip_boxes=clip_boxes,
variances=variances,
normalize_coords=normalize_coords,
subtract_mean=mean_color,
swap_channels=swap_channels)
# 2: Load some weights into the model.
# TODO: Set the path to the weights you want to load.
weights_path = './VGG_ILSVRC_16_layers_fc_reduced.h5'
model.load_weights(weights_path, by_name=True)
# 3: Instantiate an optimizer and the SSD loss function and compile the model.
# If you want to follow the original Caffe implementation, use the preset SGD
# optimizer, otherwise I'd recommend the commented-out Adam optimizer.
# adam = Adam(lr=0.001, beta_1=0.9, beta_2=0.999, epsilon=1e-08, decay=0.0)
sgd = SGD(lr=0.001, momentum=0.9, decay=0.0, nesterov=False)
# sgd = SGD(lr=0.001, momentum=0.9, decay=0.0, nesterov=True)
ssd_loss = SSDLoss(neg_pos_ratio=3, alpha=1.0)
model.compile(optimizer=sgd, loss=ssd_loss.compute_loss)
# model.compile(optimizer=adam, loss=ssd_loss.compute_loss)
# TODO: Set the path to the `.h5` file of the model to be loaded.
# model_path = 'path/to/trained/model.h5'
#E model_path = './VGG_ILSVRC_16_layers_fc_reduced.h5'
# We need to create an SSDLoss object in order to pass that to the model loader.
#E ssd_loss = SSDLoss(neg_pos_ratio=3, alpha=1.0)
#E K.clear_session() # Clear previous models from memory.
#E model = load_model(model_path, custom_objects={'AnchorBoxes': AnchorBoxes,
# 'L2Normalization': L2Normalization,
# 'compute_loss': ssd_loss.compute_loss})
# 1: Instantiate two `DataGenerator` objects: One for training, one for validation.
# Optional: If you have enough memory, consider loading the images into memory for the reasons explained above.
train_dataset = DataGenerator(load_images_into_memory=False, hdf5_dataset_path=None)
val_dataset = DataGenerator(load_images_into_memory=False, hdf5_dataset_path=None)
# 2: Parse the image and label lists for the training and validation datasets. This can take a while.
# TODO: Set the paths to the datasets here.
# The directories that contain the images.
VOC_2007_images_dir = '/mnt/ssd/pascalvoc/VOCdevkit/VOC2007/JPEGImages/'
VOC_2012_images_dir = '/mnt/ssd/pascalvoc/VOCdevkit/VOC2012/JPEGImages/'
# The directories that contain the annotations.
VOC_2007_annotations_dir = '/mnt/ssd/pascalvoc/VOCdevkit/VOC2007/Annotations/'
VOC_2012_annotations_dir = '/mnt/ssd/pascalvoc/VOCdevkit/VOC2012/Annotations/'
# The paths to the image sets.
VOC_2007_train_image_set_filename = '/mnt/ssd/pascalvoc/VOCdevkit/VOC2007/ImageSets/Main/train.txt'
VOC_2012_train_image_set_filename = '/mnt/ssd/pascalvoc/VOCdevkit/VOC2012/ImageSets/Main/train.txt'
VOC_2007_val_image_set_filename = '/mnt/ssd/pascalvoc/VOCdevkit/VOC2007/ImageSets/Main/val.txt'
VOC_2012_val_image_set_filename = '/mnt/ssd/pascalvoc/VOCdevkit/VOC2012/ImageSets/Main/val.txt'
VOC_2007_trainval_image_set_filename = '/mnt/ssd/pascalvoc/VOCdevkit/VOC2007/ImageSets/Main/trainval.txt'
VOC_2012_trainval_image_set_filename = '/mnt/ssd/pascalvoc/VOCdevkit/VOC2012/ImageSets/Main/trainval.txt'
VOC_2007_test_image_set_filename = '/mnt/ssd/pascalvoc/VOCdevkit/VOC2007/ImageSets/Main/test.txt'
# The XML parser needs to now what object class names to look for and in which order to map them to integers.
classes = ['background',
'aeroplane', 'bicycle', 'bird', 'boat',
'bottle', 'bus', 'car', 'cat',
'chair', 'cow', 'diningtable', 'dog',
'horse', 'motorbike', 'person', 'pottedplant',
'sheep', 'sofa', 'train', 'tvmonitor']
train_dataset.parse_xml(images_dirs=[VOC_2007_images_dir,
VOC_2012_images_dir],
image_set_filenames=[VOC_2007_trainval_image_set_filename,
VOC_2012_trainval_image_set_filename],
annotations_dirs=[VOC_2007_annotations_dir,
VOC_2012_annotations_dir],
classes=classes,
include_classes='all',
exclude_truncated=False,
exclude_difficult=False,
ret=False)
val_dataset.parse_xml(images_dirs=[VOC_2007_images_dir],
image_set_filenames=[VOC_2007_test_image_set_filename],
annotations_dirs=[VOC_2007_annotations_dir],
classes=classes,
include_classes='all',
exclude_truncated=False,
exclude_difficult=True,
ret=False)
# 3: Set the batch size.
batch_size = 16 # Change the batch size if you like, or if you run into GPU memory issues.
# 4: Set the image transformations for pre-processing and data augmentation options.
# For the training generator:
ssd_data_augmentation = SSDDataAugmentation(img_height=img_height,
img_width=img_width,
background=mean_color)
# For the validation generator:
convert_to_3_channels = ConvertTo3Channels()
resize = Resize(height=img_height, width=img_width)
# 5: Instantiate an encoder that can encode ground truth labels into the format needed by the SSD loss function.
# The encoder constructor needs the spatial dimensions of the model's predictor layers to create the anchor boxes.
predictor_sizes = [model.get_layer('conv4_3_norm_mbox_conf').output_shape[1:3],
model.get_layer('fc7_mbox_conf').output_shape[1:3],
model.get_layer('conv6_2_mbox_conf').output_shape[1:3],
model.get_layer('conv7_2_mbox_conf').output_shape[1:3],
model.get_layer('conv8_2_mbox_conf').output_shape[1:3],
model.get_layer('conv9_2_mbox_conf').output_shape[1:3],
model.get_layer('conv10_2_mbox_conf').output_shape[1:3]]
ssd_input_encoder = SSDInputEncoder(img_height=img_height,
img_width=img_width,
n_classes=n_classes,
predictor_sizes=predictor_sizes,
scales=scales,
aspect_ratios_per_layer=aspect_ratios,
two_boxes_for_ar1=two_boxes_for_ar1,
steps=steps,
offsets=offsets,
clip_boxes=clip_boxes,
variances=variances,
matching_type='multi',
pos_iou_threshold=0.5,
neg_iou_limit=0.5,
normalize_coords=normalize_coords)
# 6: Create the generator handles that will be passed to Keras' `fit_generator()` function.
train_generator = train_dataset.generate(batch_size=batch_size,
shuffle=True,
transformations=[ssd_data_augmentation],
label_encoder=ssd_input_encoder,
returns={'processed_images',
'encoded_labels'},
keep_images_without_gt=False)
val_generator = val_dataset.generate(batch_size=batch_size,
shuffle=False,
transformations=[convert_to_3_channels,
resize],
label_encoder=ssd_input_encoder,
returns={'processed_images',
'encoded_labels'},
keep_images_without_gt=False)
# Get the number of samples in the training and validations datasets.
train_dataset_size = train_dataset.get_dataset_size()
val_dataset_size = val_dataset.get_dataset_size()
print("Number of images in the training dataset:\t{:>6}".format(train_dataset_size))
print("Number of images in the validation dataset:\t{:>6}".format(val_dataset_size))
# Define a learning rate schedule.
def lr_schedule(epoch):
if epoch < 80:
# return 0.001
return 0.0005
elif epoch < 100:
return 0.0001
else:
return 0.00001
# Define model callbacks.
# TODO: Set the filepath under which you want to save the model.
model_checkpoint = ModelCheckpoint(filepath='ssd512_pascal_07 12_epoch-{epoch:02d}_loss-{loss:.4f}_val_loss-{val_loss:.4f}.h5',
monitor='val_loss',
verbose=1,
save_best_only=True,
save_weights_only=False,
mode='auto',
period=1)
#model_checkpoint.best =
csv_logger = CSVLogger(filename='ssd512_pascal_07 12_training_log.csv',
separator=',',
append=True)
learning_rate_scheduler = LearningRateScheduler(schedule=lr_schedule,
verbose=1)
terminate_on_nan = TerminateOnNaN()
callbacks = [model_checkpoint,
csv_logger,
learning_rate_scheduler,
terminate_on_nan]
# If you're resuming a previous training, set `initial_epoch` and `final_epoch` accordingly.
initial_epoch = 0
final_epoch = 120
steps_per_epoch = 1000
history = model.fit_generator(generator=train_generator,
steps_per_epoch=steps_per_epoch,
epochs=final_epoch,
callbacks=callbacks,
validation_data=val_generator,
validation_steps=ceil(val_dataset_size/batch_size),
initial_epoch=initial_epoch)
# 1: Set the generator for the predictions.
predict_generator = val_dataset.generate(batch_size=1,
shuffle=True,
transformations=[convert_to_3_channels,
resize],
label_encoder=None,
returns={'processed_images',
'filenames',
'inverse_transform',
'original_images',
'original_labels'},
keep_images_without_gt=False)
# 2: Generate samples.
batch_images, batch_filenames, batch_inverse_transforms, batch_original_images, batch_original_labels = next(predict_generator)
i = 0 # Which batch item to look at
print("Image:", batch_filenames[i])
print()
print("Ground truth boxes:\n")
print(np.array(batch_original_labels[i]))
# 3: Make predictions.
y_pred = model.predict(batch_images)
# 4: Decode the raw predictions in `y_pred`.
y_pred_decoded = decode_detections(y_pred,
confidence_thresh=0.5,
iou_threshold=0.4,
top_k=200,
normalize_coords=normalize_coords,
img_height=img_height,
img_width=img_width)
# 5: Convert the predictions for the original image.
y_pred_decoded_inv = apply_inverse_transforms(y_pred_decoded, batch_inverse_transforms)
np.set_printoptions(precision=2, suppress=True, linewidth=90)
print("Predicted boxes:\n")
print(' class conf xmin ymin xmax ymax')
print(y_pred_decoded_inv[i])
$ python train_vgg16.py
学習曲線を引いてこのような形になっていれば成功です。
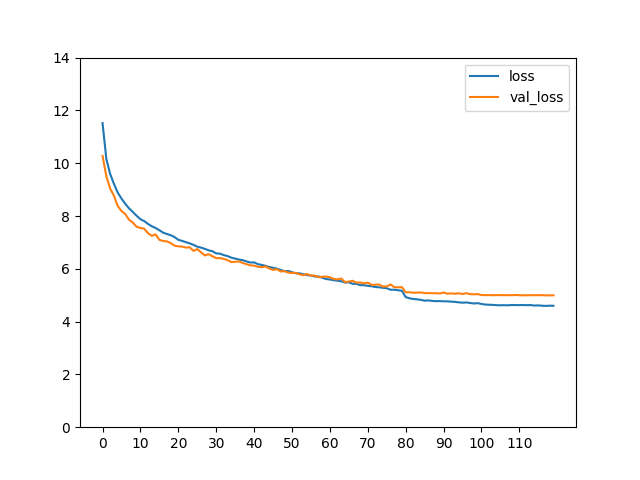
各クラスごとのAPとmAPを確認します。コードを以下に添付します。学習済みモデルのweightを引数として与えてください。
from keras import backend as K
from keras.models import load_model
from keras.optimizers import Adam
from scipy.misc import imread
import numpy as np
from matplotlib import pyplot as plt
from models.keras_ssd300 import ssd_300
from keras_loss_function.keras_ssd_loss import SSDLoss
from keras_layers.keras_layer_AnchorBoxes import AnchorBoxes
from keras_layers.keras_layer_DecodeDetections import DecodeDetections
from keras_layers.keras_layer_DecodeDetectionsFast import DecodeDetectionsFast
from keras_layers.keras_layer_L2Normalization import L2Normalization
from data_generator.object_detection_2d_data_generator import DataGenerator
from eval_utils.average_precision_evaluator import Evaluator
from keras.utils import np_utils, plot_model
import tensorflow as tf
from keras.backend.tensorflow_backend import set_session
import sys
# Set a few configuration parameters.
img_height = 512
img_width = 512
n_classes = 20
# model_mode = 'inference'
model_mode = 'training'
# TODO: Set the path to the `.h5` file of the model to be loaded.
model_path = sys.argv[1]
# K.clear_session() # Clear previous models from memory.
config = tf.ConfigProto(
gpu_options=tf.GPUOptions(
visible_device_list="0", # specify GPU number
allow_growth=True
)
)
set_session(tf.Session(config=config))
# We need to create an SSDLoss object in order to pass that to the model loader.
ssd_loss = SSDLoss(neg_pos_ratio=3, alpha=1.0)
model = load_model(model_path, custom_objects={'AnchorBoxes': AnchorBoxes,
'L2Normalization': L2Normalization,
'DecodeDetections': DecodeDetections,
'compute_loss': ssd_loss.compute_loss})
# plot_model(model, to_file='model.png', show_shapes=True, show_layer_names=True)
dataset = DataGenerator()
# TODO: Set the paths to the dataset here.
Pascal_VOC_dataset_images_dir = '/mnt/ssd/pascalvoc/VOCdevkit/VOC2007/JPEGImages/'
Pascal_VOC_dataset_annotations_dir = '/mnt/ssd/pascalvoc/VOCdevkit/VOC2007/Annotations/'
Pascal_VOC_dataset_image_set_filename = '/mnt/ssd/pascalvoc/VOCdevkit/VOC2007/ImageSets/Main/test.txt'
# The XML parser needs to now what object class names to look for and in which order to map them to integers.
classes = ['background',
'aeroplane', 'bicycle', 'bird', 'boat',
'bottle', 'bus', 'car', 'cat',
'chair', 'cow', 'diningtable', 'dog',
'horse', 'motorbike', 'person', 'pottedplant',
'sheep', 'sofa', 'train', 'tvmonitor']
dataset.parse_xml(images_dirs=[Pascal_VOC_dataset_images_dir],
image_set_filenames=[Pascal_VOC_dataset_image_set_filename],
annotations_dirs=[Pascal_VOC_dataset_annotations_dir],
classes=classes,
include_classes='all',
exclude_truncated=False,
exclude_difficult=False,
ret=False)
evaluator = Evaluator(model=model,
n_classes=n_classes,
data_generator=dataset,
model_mode=model_mode)
results = evaluator(img_height=img_height,
img_width=img_width,
batch_size=8,
data_generator_mode='resize',
round_confidences=False,
matching_iou_threshold=0.5,
border_pixels='include',
sorting_algorithm='quicksort',
average_precision_mode='sample',
num_recall_points=11,
ignore_neutral_boxes=True,
return_precisions=True,
return_recalls=True,
return_average_precisions=True,
verbose=True)
mean_average_precision, average_precisions, precisions, recalls = results
for i in range(1, len(average_precisions)):
print("{:<14}{:<6}{}".format(classes[i], 'AP', round(average_precisions[i], 3)))
print()
print("{:<14}{:<6}{}".format('','mAP', round(mean_average_precision, 3)))
$ python eval_ssd_pascalvoc.py ssd512_pascal_07+12_epoch-118_loss-4.5939_val_loss-4.9923.h5
aeroplane 0.838
bicycle 0.856
bird 0.807
boat 0.712
bottle 0.563
bus 0.871
car 0.876
cat 0.872
chair 0.627
cow 0.849
diningtable 0.75
dog 0.866
horse 0.872
motorbike 0.842
person 0.805
pottedplant 0.545
sheep 0.796
sofa 0.783
train 0.874
tvmonitor 0.779
mAP 0.789
SSDの原論文およびFerrariさんのClaimではSSD512のmAPは0.798ですから、一度流したスコアとしてはまずまずでしょう。きちんと学習が行われているようです。
Deep Learningのパラメータには大きく分けてふたつのカテゴリーがあります。ひとつはモデルの設計に関するもの、もうひとつは学習に関するものです。学習に関するパラメータで最も大切なのはオプティマイザーの選択と学習率の設定でしょう。オプティマイザーにMomentumSGDを用いたSSDの学習は比較的センシティブで、学習初期に発散することがあります。そんなときは学習率を大きめにするとうまくいくことがあり、今回もそのような調整をしています。
オリジナルのSSDはベースネットにVGG16を用いるものでしたが、SSDの基本的な考え方はVGG16に依存するものではありません。精度の向上や高速化のために別のベースネットを試すことがよく行われれます。ずいぶん長くなってしまたので、ひとまずこれくらいにして次回はベースネットを変更したモデルの学習と推測について説明したいと思います。(せっかくなのでやったことのないもので。。。DenseNetとかにしましょうか ^_^)