最深層の特徴マップの特徴量のみを使うYoloと違い、SSDは中間層から深層にかけて複数の特徴マップの特徴量を使います。浅い層には受容野の小さなアンカーボックスが設置され、小さな物体の検知を担いますが、浅い層では高次の特徴が十分に取り込めていないために精度の高い推測が難しくなります。このことが小さな物体の推測精度を悪化させ、SSDの課題とされてきました。
DSSDに代表される手法ではこの問題に対処するために、Deconvolutionの導入を行っています。Deconvolutionは重み学習付きのアップサンプラーとして働き、深層からのデータを浅い層に還流させることができます。画像認識の中でも、ピクセルレベルのクラス分類を行うセマンティックセグメンテーションではDeconvolutionを用いるのが一般的な手法となっていて、深層で得られた高次の特徴を還流させています。
#一般的には還流という言葉は正確ではないかと思いますが、ここではイメージをとらえるためにそう表現しています。
DSSDの論文では、Deconvolutionの導入の他に以下の手法が採用されています。
1. basenetをVGG16からResNet101に変更
2. Prediction Moduleの使用
3. アンカーボックスの数を増加
ResNetは言わずとしれた画像分類のブレイクスルーとなった技術で、Residual Moduleの導入で従来よりはるかに多い層数のモデルを実現し、高い性能を持つことで知られています。なので、basenetに使ってみるというのは期待できそうです。SSDとともにone stage型の物体検知の双璧をなすYoloも、YoloV3でもbasenetにResidual Moduleを導入しResNetライクな多層化を行っています。
一方でDSSDの論文では、ただ単にbasenetを導入しただけでは精度の向上はみられなかったということを報告しており、Prediction Moduleの導入とDeconvolution Moduleの導入によって、オリジナルのSSDを凌駕したと主張しています。ただ、この主張には少し疑問があります。Prediction ModuleとDeconvolution ModuleはbasenetがResNet101でなくても導入できそうです。論文ではResNet101との相性が良かったように書いていますが、VGGをbasenetにして、ablation studyをした結果が見つけられなかったので、Prediction ModuleとDeconvolutionはbasenetがVGGでも有効なのではないかという疑問が生まれます。
オリジナルのSSDでは、特徴マップからクラス推定と位置推定を行うために3x3の小さなカーネルを使用しています。この部分を強化してみたらどうだろうというのが、Prediction Moduleのアイデアです。DSSDの論文に簡単に触れられていますが、この部分を強化すると言うより、クラス推定と位置推定の誤差のバックプロパゲーションがbasenetに直接影響を及ぼすのを避けるという解釈もあるかもしれません。
Prediction ModuleについてはDSSDを参考に以下のような形にしてみました。
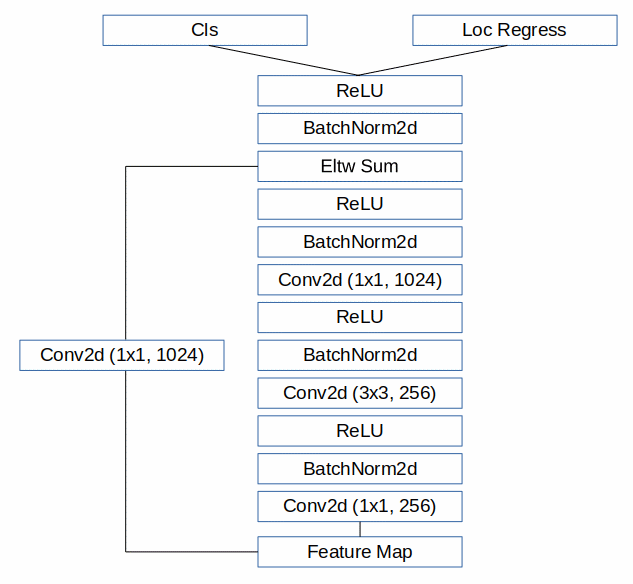
ソースコードは https://github.com/ponta256/ssd-extention-study.git からダウンロードできます。
以下の設定を使います。(train.pyおよびeval.pyの該当部分をコメントアウト)
from ssd512 import build_ssd cfg = voc512
学習と評価を行ってみます。
$ CUDA_VISIBLE_DEVICES=0 python train.py --dataset=VOC --dataset_root=/mnt/ssd/VOCdevkit/ --loss_type='cross_entropy' --weight_prefix='VOC512_PM_' --batch_size=16 --use_pred_module=True $ CUDA_VISIBLE_DEVICES=0 python eval.py --voc_root=/mnt/ssd/VOCdevkit/ --trained_model=weights/VOC512_PM_249.pth --use_pred_module=True ~snip~ AP for aeroplane = 0.8909 AP for bicycle = 0.8596 AP for bird = 0.8032 AP for boat = 0.7628 AP for bottle = 0.6172 AP for bus = 0.8925 AP for car = 0.8817 AP for cat = 0.8846 AP for chair = 0.6616 AP for cow = 0.8619 AP for diningtable = 0.7811 AP for dog = 0.8517 AP for horse = 0.8968 AP for motorbike = 0.8644 AP for person = 0.8312 AP for pottedplant = 0.5697 AP for sheep = 0.8116 AP for sofa = 0.8023 AP for train = 0.8699 AP for tvmonitor = 0.7882 Mean AP = 0.8092
0.4ポイント程度ですが、オリジナルのSSD512からの改善が見られるようです。
続いて、Deconvolution Moduleについて検討します。Deconvolution Moduleは深層からの高次の特徴を還流させることによって、小さなオブジェクトの認識率が高くなることを期待しているわけですが、SSD512で7層ある特徴抽出マップのうち四層目から一層目へ向けて還流をかけることにします。(DSSDの論文の構成とは違います)
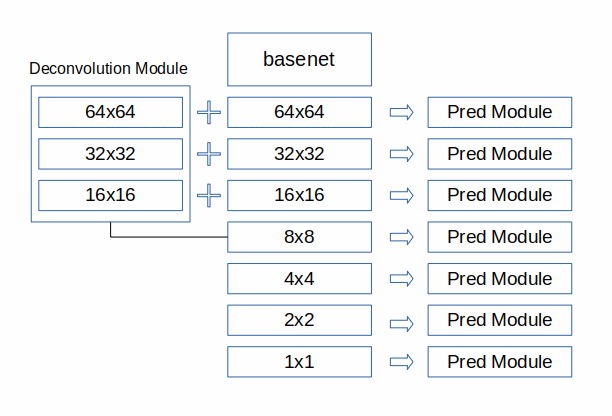
以下の設定を使います。(train.pyおよびeval.pyの該当部分をコメントアウト)
from dssd512 import build_ssd cfg = vocd512
学習と評価を行ってみます。
$ CUDA_VISIBLE_DEVICES=0 python train.py --dataset=VOC --dataset_root=/mnt/ssd/VOCdevkit/ --loss_type='cross_entropy' --weight_prefix='VOC512_DSSD_PM_' --batch_size=16 --use_pred_module=True $ CUDA_VISIBLE_DEVICES=0 python eval.py --voc_root=/mnt/ssd/VOCdevkit/ --trained_model=weights/VOC512_DSSD_PM_249.pth --use_pred_module=True ~snip~ AP for aeroplane = 0.8921 AP for bicycle = 0.8746 AP for bird = 0.7917 AP for boat = 0.7566 AP for bottle = 0.6291 AP for bus = 0.8840 AP for car = 0.8846 AP for cat = 0.8845 AP for chair = 0.6672 AP for cow = 0.8738 AP for diningtable = 0.8037 AP for dog = 0.8670 AP for horse = 0.8923 AP for motorbike = 0.8620 AP for person = 0.8316 AP for pottedplant = 0.5308 AP for sheep = 0.8337 AP for sofa = 0.7945 AP for train = 0.8857 AP for tvmonitor = 0.7991 Mean AP = 0.8119
0.3ポイント程度、精度があがっているようです。二、三度、学習と評価を行ってみたところ、最高値は0.8149。
DSSDの論文での報告値は0.815ですので、ほぼ同一のスコアを達成することができたようです。
ところで、一連の学習では、epoch=150とepoch=200で学習率をx0.1しながら、epoch=249 (250epochs)まで学習させましたが、10epochごとの学習ウェイトで評価をしたところ、以下のような結果がでています。学習率をx0.1するepoch=150でmAP大きく上昇していますが、epoch=170以降はあまり大きな変化はなく、mAPは上下に0.05程度の範囲内で揺れながら収束します。(=250epochも学習させなくてよいようです)
以下にSSD512とDSSD512(SSD512 Prediction Module Deconvolution)の学習epoch数とmAPの推移を示します。
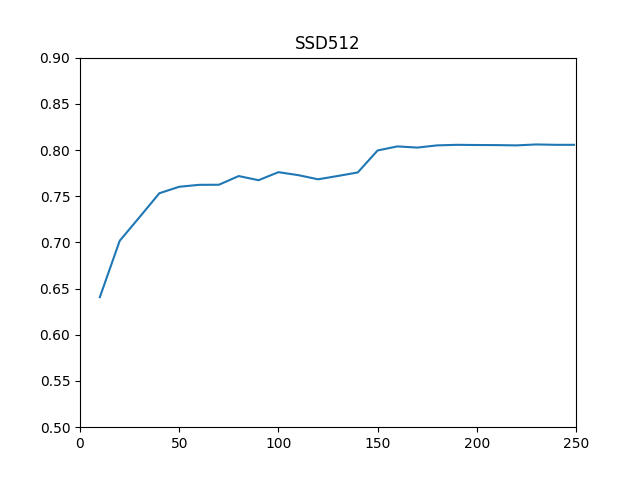
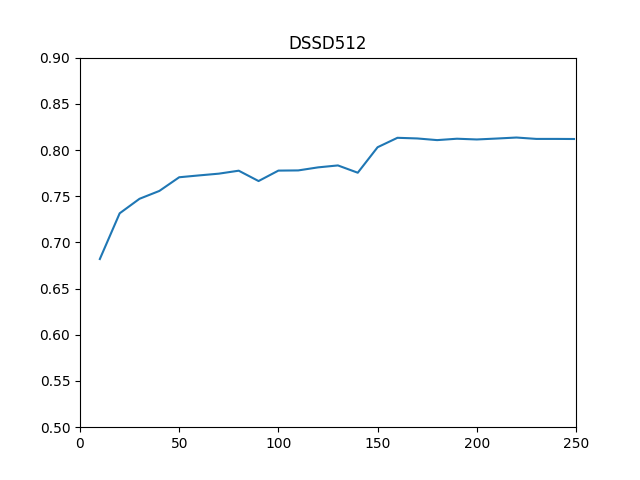
今回はSSD512にPrediction moduleとDeconvolutionを付け加えることで、精度の向上を追求してみました。DSSDの論文と同等のmAPを達成することができました。