CNNをつかった物体検知のアルゴリズムに共通するのは、入力画像に対して畳み込みを繰り返し適用し、ストライドを大きくとったり、プーリングレイヤーを適用したりしてサイズを徐々に小さくし、得られた特徴マップにPredict Moduleを適用して位置とクラスを推定するという構造です。
この特徴マップの作り方にはいくつかのタイプがあります。
a).
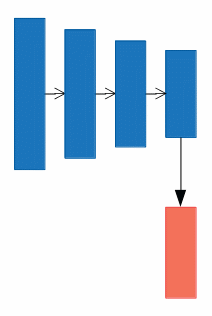
Yoloはこのタイプの代表で、CNNの最後の層のみを特徴マップとして利用し、Predict Moduleを適用します。
b).
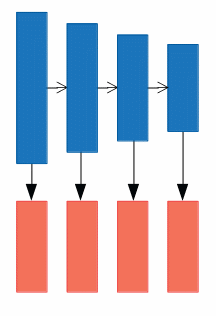
SSDはこのタイプで、サイズの違う複数の特徴マップにPredict Moduleを適用します。
a)タイプはCNNの最深層にのみPredict Moduleを適用するため、十分に抽象化された特徴を利用できる一方で、特徴マップのサイズが小さくなっているために位置的な情報が失われているという弱点があります。一方でb)タイプはPredict Moduleを複数使い、浅い層の特徴マップが小さなオブジェクトの検知を、深い層の特徴が大きなオブジェクトの検知を担います。この方法は位置的な情報を有利に使うことができる一方で、浅い層では特徴の抽象化が十分でないという弱点があります。
c).
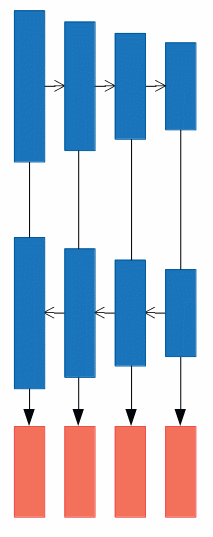
DSSDはこのタイプです。SSDの弱点を補うことを目的に、深層の特徴マップの情報を浅い層に還流して合成しています。浅い層はサイズが大きいために、深層の特徴マップはそのままではデータ構造に不一致が生じて合成できないために、Deconvolutionでサイズを大きくしています。
合成の仕方には、いくつか方法があって、 和、積、連結(concatenate)が一般的です。連結はチャネル方向につなげるやり方で、d)で出てくるFSSDではチャネル方向の連結を使っています。
合成の仕方には、いくつか方法があって、 和、積、連結(concatenate)が一般的です。連結はチャネル方向につなげるやり方で、d)で出てくるFSSDではチャネル方向の連結を使っています。
d).
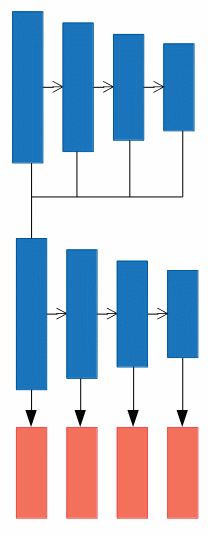
FSSDがこのタイプになります。深層からの情報をUpsamplingしながら還流し、特徴マップを作ります。合成された特徴マップをSSDと同様にDownsamplingしながら複数のPredict Moduleを適用していきます。FSSDでは合成時にチャネルの連結を用いています。
FSSDを実装し、学習してみます。前回の学習結果から、学習epochを150とし、学習率を100epochおよび130epochでx0.1することにします。
学習の結果生成されるモデルを用いて、テストデータの評価を行うと、必ずしも単調に精度が向上するわけでなく、特に学習後期では精度は細かく揺れ動きながら収束していきます。今回は以下の三つのパターンで精度の推移を測定してみました。
DSSD_SUM (DSSD型。合成に和演算を使用)
DSSD_PRODUCT (DSSD型。合成に積演算を使用)
FSSD_CONCATATE (FSSD型。合成に連結を使用)
ソースコードは https://github.com/ponta256/ssd-extention-study.git に公開してあります。train.pyとeval.pyのimport部分(コメントアウト部分)を適時選択して使用してください。
#DSSD型は前回の記事でご紹介したもので、オリジナルの論文のものとは構造が異なります。
学習と評価は以下のように行います。評価のコマンドラインのXXXの部分はepoch数が入りますが、今回はそれぞれ0~149のepochの全てで評価を行い、mAPの推移をプロットしてみました。
$ CUDA_VISIBLE_DEVICES=0 python train.py --dataset=VOC --dataset_root=/mnt/ssd/VOCdevkit/ --loss_type='cross_entropy' --weight_prefix='VOC512_DSSDS_PM_' --batch_size=15 --use_pred_module=True $ python eval.py --voc_root=/mnt/ssd/VOCdevkit/ --trained_model weights/VOC512_DSSDS_PM_XXX.pth --use_pred_module=True $ CUDA_VISIBLE_DEVICES=0 python train.py --dataset=VOC --dataset_root=/mnt/ssd/VOCdevkit/ --loss_type='cross_entropy' --weight_prefix='VOC512_DSSDP_PM_' --batch_size=15 --use_pred_module=True $ python eval.py --voc_root=/mnt/ssd/VOCdevkit/ --trained_model weights/VOC512_DSSDP_PM_XXX.pth --use_pred_module=True $ CUDA_VISIBLE_DEVICES=0 python train.py --dataset=VOC --dataset_root=/mnt/ssd/VOCdevkit/ --loss_type='cross_entropy' --weight_prefix='VOC512_FSSD_PM_' --batch_size=15 --use_pred_module=True $ python eval.py --voc_root=/mnt/ssd/VOCdevkit/ --trained_model weights/VOC512_FSSD_PM_XXX.pth --use_pred_module=True
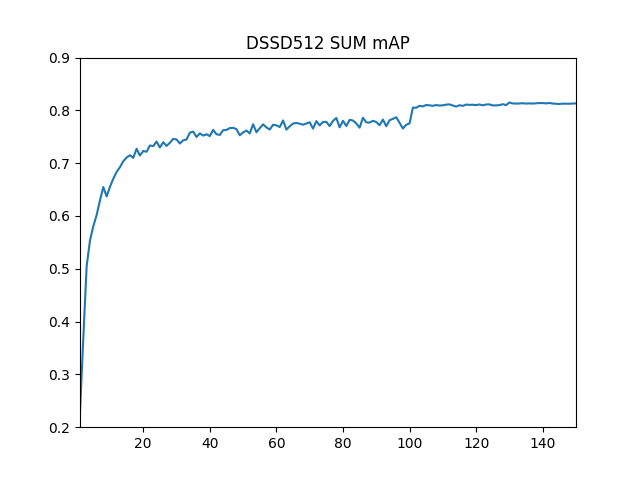
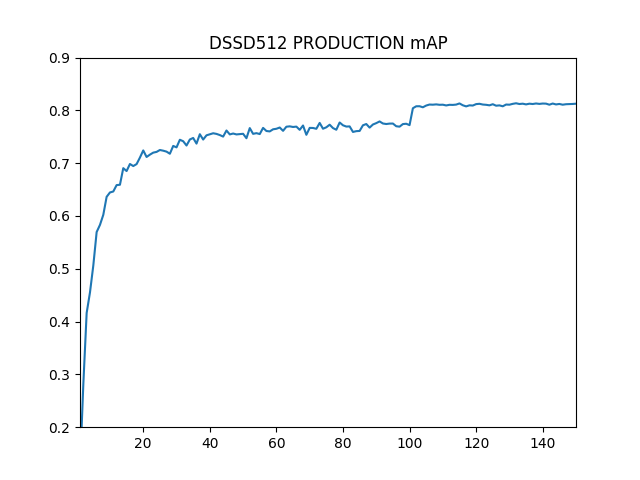
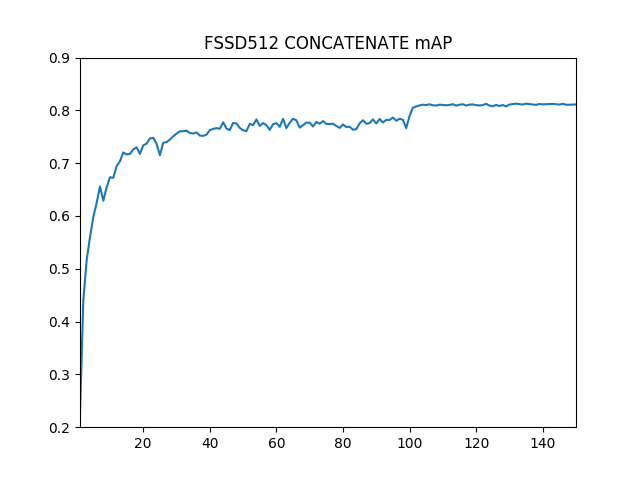
それぞれのmAPの最高到達点は0.8141, 0.8130, 0.8128でDSSDのSUM結合型が最もよい値となりましたが、差はわずかなものでした。
FSSD型にはもう少し精度の向上を期待していたのですが、思ったようには結果がでませんでした。パラメータを変更して試してみるべきところはいくつも考えられると思いますので、ご参考にしてくださればと思います。
追記:FSSD型について再度、学習と評価をしてみたところ最高でmAP=0.8197を記録しました。DSSD型では出たことのない値で、今のところの最高値となりました。