当然ですがベースネットの性能は物体検知の性能に対して大きな影響を持ちます。ここで少しディープラーニングによる分類問題モデルの変遷を整理してみます。
SSDのベースネットとして使われているVGG16は、2014年のILSVRCにおいて2位の認識精度を達成したモデルで、以降のCNNに大きな影響を与えました。VGGは同じ形のフィルタを集めてモジュール化し、それを積み上げるというシンプルな方針で構成されており、モジュール内のフィルタの繰り返しの数 (=ネットワークの深さ) をネットワークの支配的なパラメータとすることに成功しました。
具体的には、
224x224 -> 112x112 -> 56x56 -> 28x28 -> 14x14 -> 7x7
のようにプーリングなどで縦横のサイズを半分にする処理を5度行う定番のネットワーク構成を確立したのがVGG16です。この方式は後の代表的なCNNであるResNetにも採用されています。
一方で2014年のILSVRCの優勝モデルであるGoogleNetは、Inceptionモジュールと呼ばれる分岐結合ネットワークを組み合わせて作られており、 分岐構造の決定は設計者のノウハウに委ねられています。GoogleNetはまたその後発展を遂げ、Inception V3やXceptionは極めて高い認識性能を持つことで知られています。
2016年のILSVRCで2位となったResNeXtは、ResNetの強みである設計のsimplicityに、Inceptionの強みである分岐結合(split- transform-merge)ネットワークの高い認識性能を組み入れたものと言えます。
ResNeXtはResNetのモジュール構造を意識して作られており、ひとつのモジュールは下図右の構造を持ちます。(左図は対応するResNetモジュール)
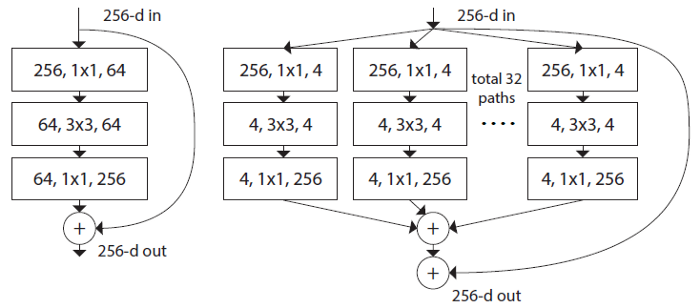
Inceptionモジュールと同等の分岐結合ネットワークを持ちながら、各パスの構造は同一のものを用いています。ResNet同様にこのモジュールを複数回積み上げることでネットワークを構成するのですが、従来のdepth、widthに加えてpath数(cardinality)をハイパーパラメータとして採用することで、見通しのよいネットワーク設計を実現しています。
ResNeXtはResNetを超える高い性能を持つことで知られており、今回はこれまで最高の性能を叩き出したFSSDのベースネットをVGG16からResNeXtに入れ替えてみることにします。
SSDは構造的にモジュール組み合わせ型のネットワークと親和性が高く、比較的簡単にベースネットの入れ替えを行うことができます。FSSDもSSDから発展して作っていますから特に難しいことはありません。
PyTorchの画像処理パッケージのTorchVisionでは、ResNetとまとめる形でResNeXtが実装され、ImageNetで学習済みのウェイトも提供されています。例えば以下のようにして学習済みウェイトを取得してください。(このコードはtorch>=1.1.0が必要です)
import torch
import numpy as np
model = torch.hub.load('pytorch/vision', 'resnext50_32x4d', pretrained=True)
model.eval()
torch.save(model.state_dict(), 'resnext50_32x4d.pth')
FSSDのベースネットをResNeXtに入れ替えて作った学習と推論のソースコードを、GitHubに置いてありますのでご参照ください。それぞれ以下のコマンドで実行します。
$ python train_fssd_resnext.py --dataset=VOC --dataset_root=/mnt/ssd/VOCdevkit/ --loss_type=cross_entropy --weight_prefix=VOC512_FSSD_RESNEXT_ --batch_size=12 --use_pred_module=True $ python eval_fssd_resnext.py --voc_root=/mnt/ssd/VOCdevkit/ --trained_model weights/VOC512_FSSD_RESNEXT_137.pth --use_pred_module=True
学習パラメータは前回と同様で、下図はmAPの推移をプロットしてみたものです。
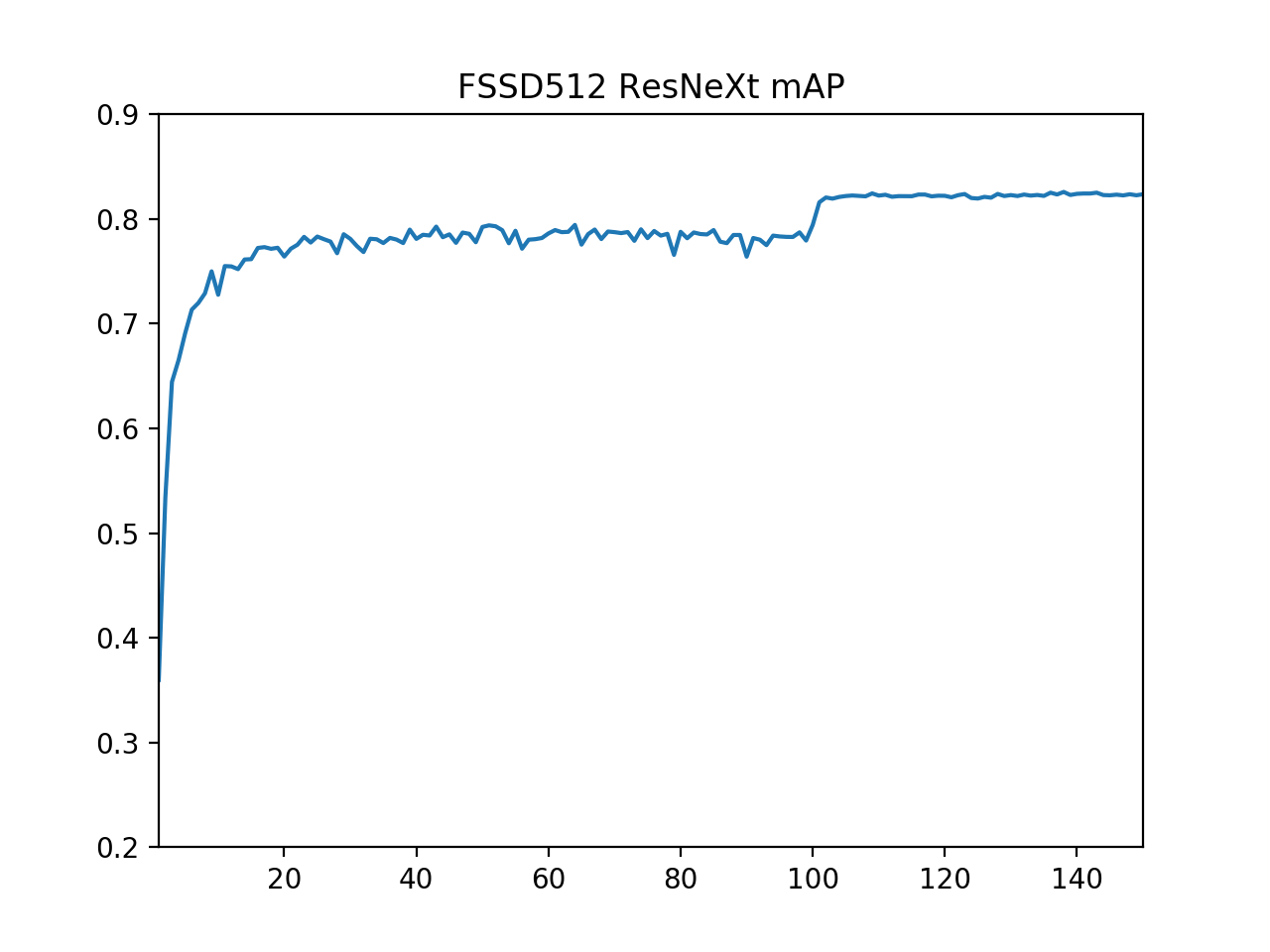 これまでの最高記録を更新し、Mean AP = 0.8258(二回学習してみたうちの最良値)を達成しました。また、VGGをベースネットに使った時に比べて、学習の進みが早く感じられました。学習エポック数を少なく調整しても同様の値を得られそうです。
これまでの最高記録を更新し、Mean AP = 0.8258(二回学習してみたうちの最良値)を達成しました。また、VGGをベースネットに使った時に比べて、学習の進みが早く感じられました。学習エポック数を少なく調整しても同様の値を得られそうです。今回はベースネットの変更の一例としてResNeXtの適用を行ってみました。画像分類用に開発された多くのネットワークは同様にしてベースネットとして用いることができます。学習済みのウェイトが用意されているものも多くありますので、ぜひ色々と試してみて頂ければと思います。