今回は物体検知シリーズのひとまずの完結編として、最終的な学習済みモデルの性能をあげるために重要なポイントを説明するとともに、カスタムデータの例としてBDD(Berkeley DeepDrive 100k)に対応する学習と推論のコードを公開します。BDDはUC Berkeleyが、自動車で録画した大量のデータからアノテーション付きのデータを作成し、公開したものです。
学習における大切なポイントのひとつは学習データそのものにあります。さまざまな環境下から大量のデータを収集し、正しくアノテーションを行うことは大変なコストがかかります。Pascal VOCやCOCOのようなパブリックデータの整備が進んでいることはとてもありがたいことですが、実際に学習したいオブジェクトや環境と一致しないときには自分でデータを収集しアノテーションを行う必要があります。
学習データの用意には、広い意味では学習データを膨らませるData Augmentationのテクニックも含まれるでしょう。これまでのご紹介したコードにも標準的なData Augmentationは含んでいますが、実際のプロジェクトの一線ではさまざまなAugmentationテクニックが駆使されています。どこかの先生が指摘していましたが、Data AugmentationがDeep Learningの美しいEnd-to-End学習スキームのあまり美しくない部分であることは否めませんが、学習モデルの推論精度をあげることに大きく貢献します。
残されたポイントは、学習対象にあわせたパラメータの調整です。たとえばBDDの画像は1280x720のサイズを持ちます。以前Pascal VOC用に設計した物体検知モデルは512x512の入力設定でした。モデルへの入力サイズを300x300から512x512に拡大した時には性能が大きく向上しました。1280x720の画像を活かす設定にすることで性能向上が期待できそうです。
SSD型の物体検知モデルにとって最も重要な調整項目はアンカーボックスです。SSDは各ステージレイヤ上に配置したアンカーボックスと学習データにあるオブジェクトの重なり(IoU)を手がかりに学習を進めていきます。標準のアルゴリズムではIoUが0.5以上あるものだけの学習を行ないますから、適切なアンカーボックスを配置できないと思った学習が行われません。
このアンカーボックスの数や形を、学習対象に応じて決めていくことで高い精度を狙うことができるのです。公開コードでは縦横の違うアンカーボックスを扱うために、アンカーボックの処理を変更しています。(layers/functions/prior_box.py) またBDDの画像は1280x720ですが、便宜上モデルへの入力を1280x768とし、入力はこのサイズにリサイズして使っています。
#このサイズだと1/2化を繰り返しても割り切れるためです。割り切れなくなったところでステージレイヤの設置をやめていますが、もっと大きなアンカーボックスを設置したい場合はさらにステージレイヤを続けます。
使用するモデルは、以前と同じResNeXt-FSSDですが、ステージレイヤの数や引き出す層を変更しています。data/config.pyのアンカーボックスの設定部分を以下に示します。設定値は参考例ですので、実際は学習データに応じて試行錯誤しながらベストのものを選んでいきます。
#アンカーボックスのアスペクト比は例として縦長のものを多く置いてみました。歩行者は得意かもしれませんが、車高の低いスポーツカーは苦手かもしれません。
bdd1280x768 = {
'num_classes': 11,
'lr_steps': (100, 130, 150),
'max_epoch': 150,
# (w,h)
'size': (1280,768),
# (h,w)
'feature_maps': [(48,80), (24,40), (12,20), (6,10), (3,5)],
'steps': [16, 32, 64, 128, 256],
'anchor_sizes': [32, 64, 128, 256, 512],
'box': [5, 5, 5, 5, 5],
'aspect_ratios': [(0.5,1.0,1.5,2.0,2.5),
(0.5,1.0,1.5,2.0,2.5),
(0.5,1.0,1.5,2.0,2.5),
(0.5,1.0,1.5,2.0,2.5),
(0.5,1.0,1.5,2.0,2.5)],
'variance': [0.1, 0.2],
'clip': True,
'name': 'BDD',
}
経験上、ひとつ重要なポイントをあげておきましょう。上記の設定例でもっとも浅いステージレイヤはH,W=(48,80)のグリッドを構成しています。元々の入力サイズがH,W=(768, 1280)だったことを考えると、ひとつのグリッドが16x16のサイズになります。このグリッドの上にアンカーボックスを設置していくのですが、ひとつのグリッド上でのアスペクトの異なるアンカーボックスの配置を図示するとこんな感じになります。

上記の設定では隣合うアンカーボックスが重なりあうように作っています。隣り合う三つのグリッド上のアンカーボックスを重ねて表示すると以下のようになります。
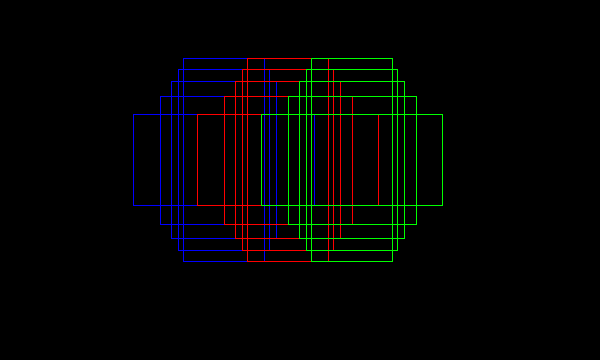
この重なり具合のバランスをうまく取り、候補となるアンカーボックスと学習データ中のオブジェクトとのIoUを大きくすることが重要なのです。(パラメータでいうとsteps, anchor_sizes, aspect_rations)
今回のコードはいつものGitHubに置いてあります。ResNeXtのpretrainedウェイト(resnext50_32x4d.pth)をweightsの下に置き、BDDのデータを/mnt/ssd以下に置くことを想定した、学習のためのコマンドは以下の通り。(batch_sizeはGPUのメモリサイズに応じて変えてください)
$ CUDA_VISIBLE_DEVICES=0 python train_bdd.py --weight_prefix=BDD1280_ --batch_size=8
3エポックほど学習して、推論してみたのが以下の結果です。
$ CUDA_VISIBLE_DEVICES=0 python pred_bdd.py --trained_model=weights/BDD1280_2.pth ce46abf5-60a664ae.jpg --confidence_thresh=0.2 [415.92377 329.04257 502.94916 397.7107 ] tensor(0.8938) car [494.7047 335.94577 526.7527 369.91336] tensor(0.8869) car [1027.0021 337.89703 1120.1086 393.16125] tensor(0.4312) car [ 937.7295 335.13718 1009.41394 382.30765] tensor(0.3465) car [1199.7373 344.98965 1279.0842 410.4869 ] tensor(0.3064) car [325.1724 324.3158 354.42175 348.1307 ] tensor(0.2986) car [ 12.810516 326.43558 65.90016 349.636 ] tensor(0.2841) car [413.11337 333.74448 430.0153 347.4073 ] tensor(0.2636) car [249.97311 323.83926 283.2886 346.79236] tensor(0.2592) car [782.54095 337.47507 809.06555 360.97693] tensor(0.2582) car [ 981.97253 337.19232 1044.2208 383.9483 ] tensor(0.2183) car [806.02325 340.3947 844.5136 367.0659 ] tensor(0.2086) car [ 38.670067 327.00745 71.28928 347.9672 ] tensor(0.2035) car [364.0655 326.34375 382.8531 345.4213 ] tensor(0.2006) car [493.36868 300.9129 504.27814 316.19363] tensor(0.3380) traffic light [393.98975 310.80786 405.80594 324.72968] tensor(0.2558) traffic light [815.8112 250.5596 841.8939 277.3361] tensor(0.3759) traffic sign [1185.5919 144.57173 1278.6012 256.4125 ] tensor(0.2577) traffic sign

順調に学習ができているようです。
物体検知はなかなか奥深い分野ですが、クラスの数が限定され、かつ十分な学習データが用意できる時には、人間と近い精度を出せるようになってきた実感があります。今後も応用の幅を広げ、多くのソリューションやサービスの基盤となっていくことを期待しています。