前回、姿勢推定関連の論文を独断で厳選するならこの四つという話をしました。今回はこのうちの「Simple Baselines for Human Pose Estimation and Tracking」のPose Estimationの部分(以下、Simple Baseline)にフォーカスして説明したいと思います。
姿勢推定の本質的なタスクは「関節」を見つけることにあります。もっと正確に言えば、右手首、左肩、右膝のようなあらかじめ決めた関節を見つけ出し、その場所を特定することです。対象を一人に限れば(= Single Person Pose Estimation)、同じ種類の関節は一度しか出てきませんし、画像の中にそこそこの大きさで人物が入っていることが期待できるので、話をだいぶ簡単にして考えることができます。
Single Person Pose Estimationでは人物検知のアルゴリズムが前処理を行って、ちょうどいい矩形に切り出してくれることを想定します。以下は実際の検知例です。この矩形部分を切り出して使うのです。

切り出した画像から人物の各関節を見つけていくのですが、画像の特徴量から関節を見つけだすというタスクは、画像から物体を探す物体検知タスクとよく似ています。物体検知の場合は大きさのある物体を検知してそのバウンディングボックスを推定することになりますが、関節の場合はその場所は点座標になります。
一般にディープラーニングの手法を用いて特徴抽出を行って推定を行う際には、畳み込みをしながら特徴マップのサイズを小さくしていきます。特徴マップを小さくすることで受容野を大きくし、広いコンテキストから推定を行うことができるようになるという利点があるためです。例えば左肘を見つけるのに左肘の周辺だけを見ているより、もっと広い視野で眺めた方が正しい推定を行うことができそうなのは直感的にも納得いきますね。
ところがこの手法には問題が生じることがあります。特徴マップを小さくすることで、場所の粒度が失われてしまうのです。姿勢推定の例でいえば、小さくした特徴マップで左肘がありそうだということを推定したのはいいけれども、それが元のサイズの画像座標のどこであったかの情報が失われてしまうのです。実はこれはいくつかの画像認識タスクに共通の課題で、解決手法もいくつか提案されています。そのひとつに逆畳み込み(deconvolution)を使うものがあります。畳み込みではそのパラメータのひとつであるstrideを2以上にすると特徴マップが小さくなっていきましたが、逆畳み込みでは逆に特徴マップを大きくすることができるのです。
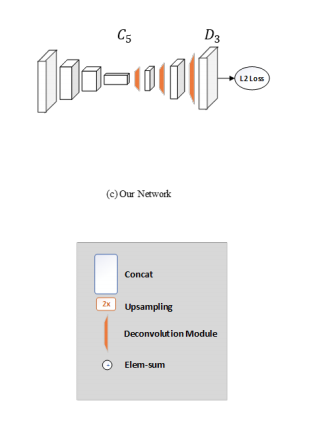
特徴マップを大きく復元するためには単純なアップサンプリングを使う方法もあります。アップサンプリングと逆畳み込みの違いは、アップサンプリングが計算による補完によって拡大を行うのに対し、逆畳み込みは重みの学習を伴うことにあります。それまでの手法はショートカット付きのアップサンプリング(Hourglass構造)を使っていたのに対し、Simple Baselineは逆畳み込みを使ったのが目立った違いとなっています。(ただしセマンティックセグメンテーションなど他のタスクでは使われている手法であり、Simple Baselineの著者も新規性は主張していません)
右図がSimple Baselineの構造です。本当にシンプルです。
前回も説明したように、Simple BaselineはMicrosoftが考案した手法で、同じチームは続けてHRNetと名付けられた高精度のモデルを発表しています。HRNetの公開コードの中にはSimple Baselineのコードも含まれていますので、今回はそのレポジトリから動作を確認してみます。
こちらのGitHubの手順に従って環境を用意します。少し面倒ですが大変丁寧に書かれてありますのできっちり追っていけば必ずうまくいきます。ただせっかくなので、こうした環境を作るときにハマるポイントをあげておきます。
ディープラーニングを用いた機械学習には事実上、GPUが必須です。現行で一番使い勝手がいいのがNVIDIAのGPUになり、GeForce、Titan、Quadro、Teslaの順に高価なものになっていきます。Sigfossでは、本番運用環境にはQuadroを、学習用にはGeForceとTitanを多く使っています。独断で言うなら、高価なQuadroやTeslaの付加価値は計算性能というより、高耐久性だと思っています。なので学習用に枚数稼ぎたいときにはコスパ重視でGeForceやTitanを重宝しています。
ディープラーニングを用いた機械学習には事実上、GPUが必須です。現行で一番使い勝手がいいのがNVIDIAのGPUになり、GeForce、Titan、Quadro、Teslaの順に高価なものになっていきます。Sigfossでは、本番運用環境にはQuadroを、学習用にはGeForceとTitanを多く使っています。独断で言うなら、高価なQuadroやTeslaの付加価値は計算性能というより、高耐久性だと思っています。なので学習用に枚数稼ぎたいときにはコスパ重視でGeForceやTitanを重宝しています。
さて、NVIDIAのGPUには「世代」があります。PascalアーキテクチャとかTuringアーキテクチャとか名前はついているのですが、GeForceとTitanではモデル名の頭につくGTX/RTXで区別がつきます。で、GPUを動かすためにはnvidiaのdriverを入れる必要があるのですが、driverが古いと新しいGPUが動かなかったりします。基本は新しいdriverなら大丈夫なのですが、driverとGPUの世代には相性があるというのが最初のポイントです。nvidia-smiコマンドできちんとGPUが認識されることをまずは確保しましょう。
次にポイントになるのが、CUDAのバージョンです。もともとはグラフィックス用に開発されたGPUをそれ以外の用途にも応用しやすくなったのは、CUDAフレームワークの功績です。なのでNVIDIAのGPUを使うときにはCUDAが必須なのですが、CUDAにも当然いくつかのバージョンがあります。 CUDAには先程述べたGPU driverとのコンパチビリティがあるので注意です。
次にポイントになるのが、CUDAのバージョンです。もともとはグラフィックス用に開発されたGPUをそれ以外の用途にも応用しやすくなったのは、CUDAフレームワークの功績です。なのでNVIDIAのGPUを使うときにはCUDAが必須なのですが、CUDAにも当然いくつかのバージョンがあります。 CUDAには先程述べたGPU driverとのコンパチビリティがあるので注意です。

一見CUDAも新しいバージョン選んどけば良さげなのですが、ここからがややこやしいのです。GitHubなどから参考にするコードは使用するフレームワーク(PyTorchなど)のバージョンが指定されていることがあります。このバージョンがCUDAのバージョンと紐付いていることがあり、最新のCUDAではそのバージョンのフレームワークが動かなかったりすることがあるのです。
これはもうサイエンスではないので、何度か辛抱強くやってると大丈夫なパターンが見えてきます。ついでに言えばPythonのバージョンやnumpy、opencvといったメジャーなモジュールのバージョンも問題になることがあります。繰り返しますが辛抱強く環境を作ることです。あるプログラムのために苦労して作った環境が、他のプログラムが動かない環境だということは十分にあるので、dockerやvirtualenvを使ったライトウェイトな仮想環境を使えるようになることがとても重要です。
これはもうサイエンスではないので、何度か辛抱強くやってると大丈夫なパターンが見えてきます。ついでに言えばPythonのバージョンやnumpy、opencvといったメジャーなモジュールのバージョンも問題になることがあります。繰り返しますが辛抱強く環境を作ることです。あるプログラムのために苦労して作った環境が、他のプログラムが動かない環境だということは十分にあるので、dockerやvirtualenvを使ったライトウェイトな仮想環境を使えるようになることがとても重要です。
話を戻しましょう。うまく環境ができたら、Simple Baselineの学習を行ってみます。
$ python tools/train.py --cfg experiments/coco/resnet/res50_256x192_d256x3_adam_lr1e-3.yaml GPUS '(0,)'
標準の設定ではGPUを4枚使う設定になっているので、手持ちの環境と違う場合は設定ファイルの内容を変更するか、上記のようにGPUの指定をオーバーライドしてあげます。配布されている学習済みのモデルを使ってCOCO validationセットの評価をしてみます。
$ python tools/test.py --cfg experiments/coco/resnet/res50_256x192_d256x3_adam_lr1e-3.yaml TEST.MODEL_FILE models/pytorch/pose_coco/pose_resnet_50_256x192.pth TEST.USE_GT_BBOX False GPUS '(0,)' ~snip~ Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets= 20 ] = 0.704 Average Precision (AP) @[ IoU=0.50 | area= all | maxDets= 20 ] = 0.886 Average Precision (AP) @[ IoU=0.75 | area= all | maxDets= 20 ] = 0.783 Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets= 20 ] = 0.671 Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets= 20 ] = 0.772 Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 20 ] = 0.763 Average Recall (AR) @[ IoU=0.50 | area= all | maxDets= 20 ] = 0.929 Average Recall (AR) @[ IoU=0.75 | area= all | maxDets= 20 ] = 0.834 Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets= 20 ] = 0.721 Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets= 20 ] = 0.824 | Arch | AP | Ap .5 | AP .75 | AP (M) | AP (L) | AR | AR .5 | AR .75 | AR (M) | AR (L) | |---|---|---|---|---|---|---|---|---|---|---| | pose_resnet | 0.704 | 0.886 | 0.783 | 0.671 | 0.772 | 0.763 | 0.929 | 0.834 | 0.721 | 0.824 |
論文で示された結果と一致しています。最後に単一のファイルに推論をかけて結果を描画するプログラムをこちらに用意しましたのでそれを使ってみます。
$ python tools/pred.py --cfg experiments/coco/resnet/res50_256x192_d256x3_adam_lr1e-3.yaml sample.jpg TEST.MODEL_FILE models/pytorch/pose_coco/pose_resnet_50_256x192.pth

うまく関節がとれているのがわかります。
今回はSimple Baselineを題材に姿勢推定のコードを動かすところまでを解説してみました。姿勢推定は画像認識タスクの中では少しマイナーですが、広い応用範囲が検討されています。今後しばらくは姿勢推定のお話を続けようと思います。