前回、KerasによるSSD実装を紹介し、SSDを改良するためにベースネットの変更を試すことが有効であるというお話をしました。今回は実際にベースネットを変更し、モデルウェイトを学習してみます。また、今回はKeras版のSSDでなく、KerasとならぶメジャーなDeep LearningフレームワークであるPytorchのSSD実装を用います。
PytorchはDefine by Runと呼ばれる設計思想を採用しているフレームワークで、Facebookが中心となって開発しています。コーディングのお作法はPFNが開発しているChainerに似ていて、(真相は知りませんが) もともとChainerのフォークだという話を聞いたことがあります。私自身、以前はChainerをずいぶん使っていたのですが、最近はKeras、Pytorchを使うことが多くなりました。どうしてもユーザーが多いフレームワークの方が情報が得やすいのが理由ですが、Chainerは優れたフレームワークと思いますので、PFNにはインターネットの巨人に負けずに頑張って欲しい。
さて、Pytorch版のSSDですが、有名なのはAlexander deGrootさんによる実装のようです。これを使ってベースネットの変更をしてみましょう。
YoloやSSDのような、シングルショット型の物体検知のネットワークモデルを設計し、学習して精度を出すことは思いの外簡単ではありません。バウンディングボックスの位置と物体のクラスの誤差をひとつのロスとしてまとめるという、ある意味強引なことをしているせいかもしれません。ディープラーニングは理屈で追い込んでのデバッグが難しく、いきなり複雑なモデルを設計して学習してもうまくいかず、手詰まりになってしまうこともあります。
私が取っているアプローチは、まずは簡単で小さなモデルを実装して学習を行い、精度はともかくとして一度学習に成功させてから、徐々に目標とするネットワークモデルに近づけていくスタイルです。急がば回れ戦法ですね。^_^
前回ご紹介したKerasのSSD実装にはSSD7という小さなモデルの例が含まれています。実際に私がKeras版SSDに新たなベースネットを実装した際には、このSSD7からスタートして変更と学習を繰り返し、少しずつ目標のネットワークモデルに近づけていきました。通常SSDの学習をする際にはベースネットにあらかじめImagenetなどで学習した事前学習済みウェイトを流し込んでから学習をするのですが、SSD7はコンパクトな作りで事前学習済みのウェイトなしで学習が可能です。
今回はこのSSD7をPytorch版のSSDのベースネットとして実装してみます。SSD7の実装と学習に成功すれば徐々に複雑なモデルへと発展させることができるでしょう。
最初にオリジナル実装の動作確認をしましょう。GitHubのレポジトリからPytorch版SSDのソースコードをcloneします。ベースネット(VGG16)の事前学習済みウェイトもダウンロードしてください。
$ git clone https://github.com/amdegroot/ssd.pytorch.git $ wget https://s3.amazonaws.com/amdegroot-models/vgg16_reducedfc.pth
オリジナル実装を現在の安定版のPytorch(version 1.0)で動かすには少しコードの修正が必要でした。変更したコードをGitHubに置いておきましたので、適当な場所にcloneして置き換えます。
$ git clone https://github.com/ponta256/pytorch-ssd7.git
$ CUDA_VISIBLE_DEVICES=1 python train.py --dataset=VOC --dataset_root=/mnt/ssd/pascalvoc/VOCdevkit/ ~ snip ~ iter 0 || Loss: 28.6335 || timer: 0.2097 sec. iter 10 || Loss: 16.0207 || timer: 0.2069 sec. iter 20 || Loss: 16.9850 || timer: 0.2301 sec. iter 30 || Loss: 14.1764 || timer: 0.2108 sec. iter 40 || Loss: 11.8755 || timer: 0.2102 sec. iter 50 || Loss: 10.9065 || timer: 0.2069 sec. iter 60 || Loss: 10.7621 || timer: 0.2082 sec. iter 70 || Loss: 10.0153 || timer: 0.2153 sec. iter 80 || Loss: 10.9170 || timer: 0.2084 sec. iter 90 || Loss: 8.7300 || timer: 0.2094 sec. ...
放置するとiter120,000まで学習を続けます。学習曲線を引いてみます。
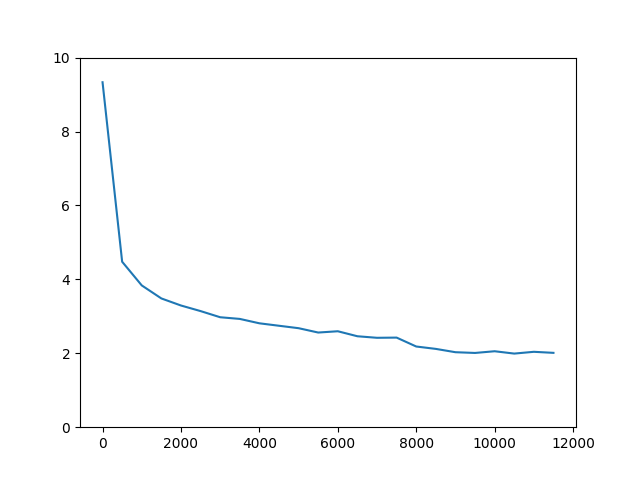
物体検知の精度を測る指標としてはmAP(mean Average Precision)があります。state of the artのモデルではmAPは0.80を超えています。今回のSSD300実装では0.77 (オリジナルの論文も0.77)とのレポートなので、これに近い値がでればよいことになります。
$ python eval.py --trained_model=weights/VOC.pth --voc_root=/mnt/ssd/pascalvoc/VOCdevkit/ ~ snip ~ AP for aeroplane = 0.8284 AP for bicycle = 0.8358 AP for bird = 0.7657 AP for boat = 0.6960 AP for bottle = 0.5078 AP for bus = 0.8508 AP for car = 0.8571 AP for cat = 0.8770 AP for chair = 0.6201 AP for cow = 0.8053 AP for diningtable = 0.7777 AP for dog = 0.8608 AP for horse = 0.8728 AP for motorbike = 0.8342 AP for person = 0.7871 AP for pottedplant = 0.5100 AP for sheep = 0.7665 AP for sofa = 0.7904 AP for train = 0.8635 AP for tvmonitor = 0.7762 Mean AP = 0.7742
一発でこんなに良い値がでることは珍しいのですが、素晴らしいスコアで、問題なく学習できているようです。
続いてSSD7の実装を行います。SSDは受容野の大きさの違う複数の特徴マップから分岐する形で、バウンディングボックスとクラスの推測を行います。標準のSSDはVGG16をベースネットに用い、追加のネットワークを加えて6つの特徴マップからの推測を行なっていますが、今回のSSD7では4つの特徴マップだけを使うことにします。畳み込み層の数もぐっと削り、こんなモデルとします。
SSD7(
(base): ModuleList(
(0): Conv2d(3, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace)
(3): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(4): Conv2d(32, 48, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(5): BatchNorm2d(48, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(6): ReLU(inplace)
(7): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(8): Conv2d(48, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(9): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(10): ReLU(inplace)
(11): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(12): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(14): ReLU(inplace)
(15): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(16): Conv2d(64, 48, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(17): BatchNorm2d(48, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(18): ReLU(inplace)
(19): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(20): Conv2d(48, 48, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(21): BatchNorm2d(48, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(22): ReLU(inplace)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(48, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(26): ReLU(inplace)
)
(loc): ModuleList(
(0): Conv2d(64, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): Conv2d(48, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(2): Conv2d(48, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): Conv2d(32, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
(conf): ModuleList(
(0): Conv2d(64, 84, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): Conv2d(48, 84, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(2): Conv2d(48, 84, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): Conv2d(32, 84, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
(softmax): Softmax()
)ベースネットの14, 18, 22, 26層の特徴マップから引き出して位置とクラスを学習するための畳み込み層と接続します。学習をしてみましょう。(ssd7のコードは先ほどのGitHubのレポジトリに含まれています。すいません肝心のモデルの定義ファイルが抜けてたので足しました。2019-05-18)
CUDA_VISIBLE_DEVICES=0 python train_ssd7.py --dataset=VOC --dataset_root=/mnt/ssd/pascalvoc/VOCdevkit/ ~ snip ~ iter 0 || Loss: 19.8675 || timer: 0.1143 sec. iter 10 || Loss: 16.1234 || timer: 0.0686 sec. iter 20 || Loss: 15.4959 || timer: 0.0844 sec. iter 30 || Loss: 14.7978 || timer: 0.0883 sec. iter 40 || Loss: 14.3634 || timer: 0.0743 sec. iter 50 || Loss: 14.0006 || timer: 0.1233 sec. iter 60 || Loss: 13.4887 || timer: 0.0879 sec. iter 70 || Loss: 12.8604 || timer: 0.0718 sec. iter 80 || Loss: 12.7472 || timer: 0.0760 sec. iter 90 || Loss: 11.7383 || timer: 0.0828 sec. ...
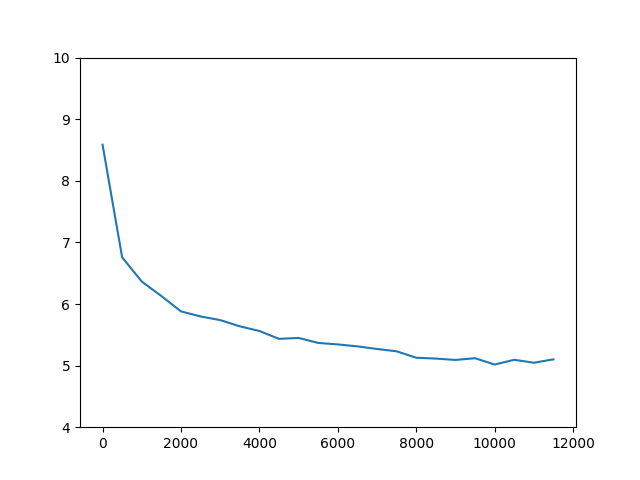
KerasのSSD7の例ではクラス数を絞り、udacityデータ使った学習を行なった例を示していますが、今回はPascal VOCで学習していますので、他のモデルと同じようにmAPを測ってみます。単純なモデルですから精度は期待していません。ここから発展させるベースとして、モデルの学習に成功し、物体検知が成功していれば十分。学習に失敗したときのmAPはほぼゼロに近くなりますから、0.20以上の値がでればまずは成功と考えてよいでしょう。
$ python eval_ssd7.py --trained_model=weights/VOC.pth --voc_root=/mnt/ssd/pascalvoc/VOCdevkit/ ~ snip ~ AP for aeroplane = 0.4626 AP for bicycle = 0.4436 AP for bird = 0.1657 AP for boat = 0.2233 AP for bottle = 0.0956 AP for bus = 0.4548 AP for car = 0.5842 AP for cat = 0.4306 AP for chair = 0.1760 AP for cow = 0.3202 AP for diningtable = 0.3279 AP for dog = 0.3550 AP for horse = 0.5273 AP for motorbike = 0.5315 AP for person = 0.4625 AP for pottedplant = 0.0806 AP for sheep = 0.3977 AP for sofa = 0.3500 AP for train = 0.4893 AP for tvmonitor = 0.4010 Mean AP = 0.3640
学習はできているようです。単発の写真に対して推論をかけてバウンディングボックスを表示してみます。
python pred_ssd7.py

あまり良い結果ではないですが、動作はしていますね。ここをスタートにもっと複雑なモデルに発展させていくと、こんな結果がでるようになります。

今回はSSDのベースネットを変更する手法として、PytorchのSSDに簡単なモデル(SSD7)を実装して学習する手法を解説しました。ベースネットをResNetやMobilenet、 Densenetなどに変更するのはここから少しずつ発展させていけばよいのです。その説明はまた次回以降に。